Ollama is an open-source local AI platform that enables you to run large language models (LLMs) directly on your own device. It can use either VRAM or System RAM however if you use system ram expect things to be much slower. Utilizing a GPU’s parallel execution versus a CPU’s sequential execution is much better and will give you better results in terms of speed and efficiency.
Install Ollama on this site: https://ollama.com/download/windows
After it installs to your computer just run the OllamaSetup.exe program and it will fully install Ollama on your computer. You can search it up in the windows search bar after and if it is there then it is installed. After installation it should have ran ollama automatically but if it did not then just click open to start it up.
Open command prompt and type ollama
ollama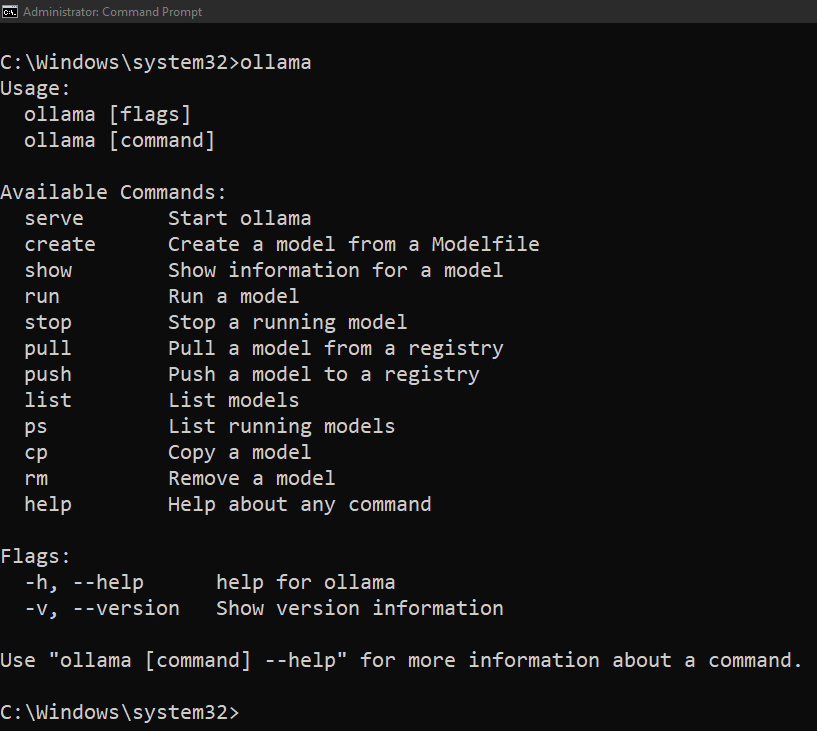
Typing this command will give you everything you need to run models locally on your computer. Lets start by checking the version of ollama that we have installed.
ollama --version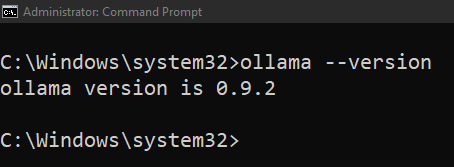
Lets start running our first model. I will go to the official ollama site and select one of the models. Click on a model that interests you and grab its full name. I will use deepseek-r1:7b
Go back to the command prompt and insert this command. This will check if we have this model installed on our computer. If we do not have it installed it will automatically install it for us then it will run the model after installation has completed. Installation may take a long time depending on how big the model is. An important thing to note is that on Windows, ollama runs as a background service by default. This means you don’t need to manually start it. If the ollama service isn’t already running, it will automatically start when you run a command like ollama run.
ollama run deepseek-r1:7bIf we wanted to just download the model without running it we would use pull instead of run:
ollama pull deepseek-r1:7b
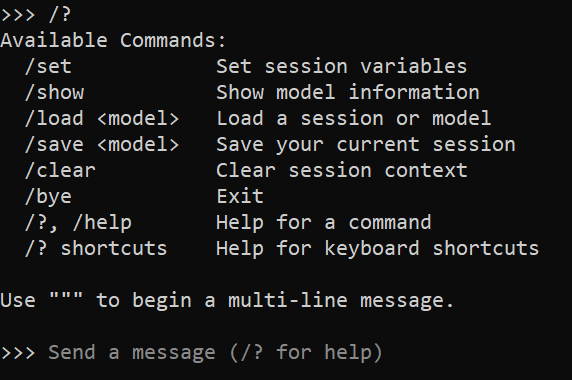
Once we are in the model we can type and interact with the model. If you would like help type /?
/?
We will leave the model by typing /bye
/bye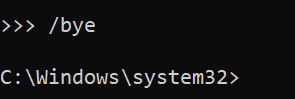
You can mess around with some of the commands if you would like. Some of these commands are useful and will tell you information about what is going on.
This lists all running models
ollama psThis lists all models regardless if it is running or not
ollama listThis stops a running model. We will use it to stop our model
ollama stop deepseek-r1:7bLets remove our model using this command:
ollama rm deepseek-r1:7b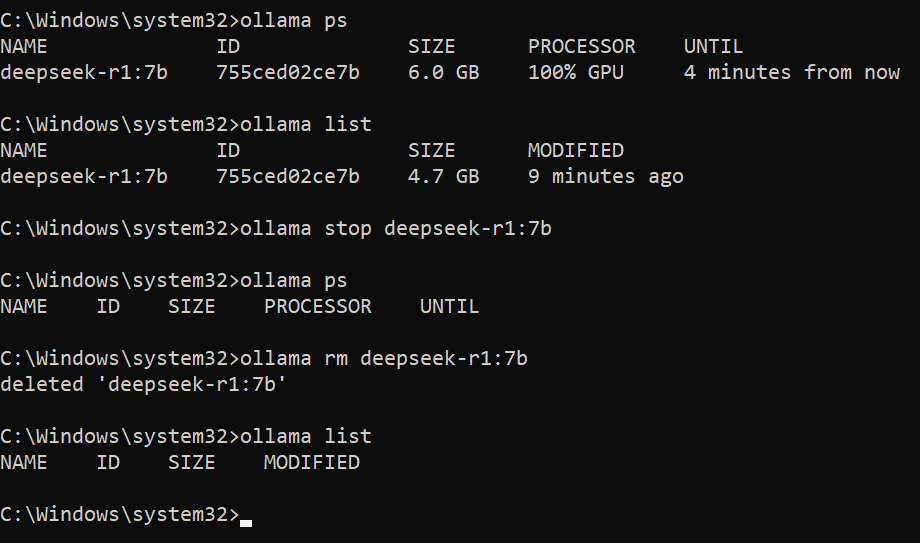
Lets pull a different model.
ollama run qwen3:14bI will exit out of this model and show information about this model that we just pulled and ran
ollama show qwen3:14bBecause we exited out of the model we simply run the ollama run command to get back into the model.
ollama run qwen3:14b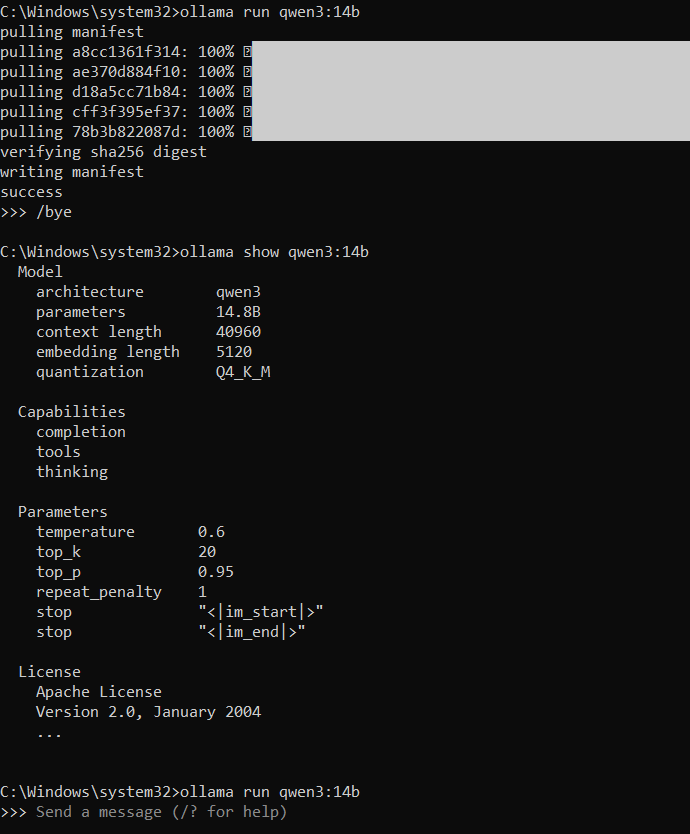
Running ollama models on your own computer is straightforward. Bigger models with more parameters need more memory and power, so it’s best to pick one that fits what your hardware can handle. Using a GPU can greatly speed up processing compared to relying on system RAM and CPU alone. Starting with smaller models to test performance and gradually moving to larger ones is a good way to find the right balance for which models you can run. Running models locally also gives you privacy and control since your data stays on your machine.